发布日期:2025-07-01 11:22 点击次数:66

 奇米777me
奇米777me
腾讯元宝打定了抱紧DeepSeek大腿不放胆的意见。
就在3月26日,元宝迎来紧要更新,再次赶在第一时候接入DeepSeekV3的“小版块更新”版块V3-3024,与此同期,元宝还同步接入了自研的混元T1郑再版。
对DeepSeek的牢牢跟进,是因为元宝正在切切实实享受到这一策略带来的平正。在本年年头的民企谈话会上,马化腾和梁文锋作念了回“同桌”,并排而坐。在那4天之前,2月13日,腾讯元宝晓谕接入DeepSeek。
莫得东谈主猜测,腾讯此举让元宝像坐上火箭,扶摇直上三沉,一度登上苹果垄断商店中国区免费榜榜首。前不久的财报会上,腾讯总裁刘炽平披露元宝的日活激增当先20倍。

自此之后,“自研+开源”的交融模式成为腾讯最新的AI策略,即通过与自己丰富居品生态的交融,也通过不同模子之间的协同互补,达成用户侧的体验莳植。
另一方面,从此次V3更新和混元T1郑再版的上线,能看出来另一种“交融”的趋势,那即是推理模子和通用模子的彼此围聚。
将来究竟是属于通用模子的,照旧推理模子的,亦或是其他黑马?这也许根柢即是一个伪命题。
当你有轮子的时候,不必两条腿走路。
DeepSeek将在掀翻大师“推理热”之后,再度掀翻“交融”热吗?
01
冗忙的元宝
不得不说,元宝跟得太紧了。
DeepSeek在3月24日晚上倏得上新V3的“小版块更新“,也即是V3-0324。
到了3月26日,元宝就如故接入了V3-0324,何况还同步接入了腾讯自研的混元T1。一个非推理模子,一个推理模子;一个外部模子,一个自研模子。元宝算是把组合玩领悟了。
V3此次的更新说是“小版块更新”,悄无声气地倏得在开源平台HuggingFace上线,其实是来了个大的,升级幅度并不小。一又友说“粗率吃点”,你认为是速冻饺子,其实端上来个毛血旺。

凭据DeepSeek的官方时间证实,V3-0324在数学、百科常识、代码任务上施展都优于前代,尤其是在数学和代码类评测集上得分当先OpenAI的GPT-4.5和Anthropic的Claude-Sonnet-3.7。
最有料想的是,V3-0324固然不是推理模子,可是有R1的滋味。官方时间证实里点出的四大亮点“推理才略”“前端诱惑才略”“汉文合作才略”“汉文搜索”都落在了R1的上风范围内。
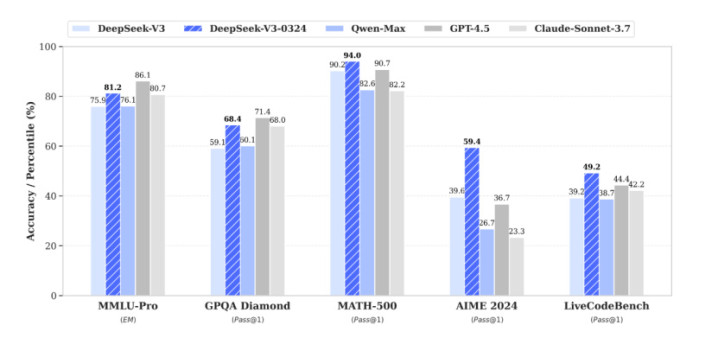
在试验测试中奇米777me,V3-0324也比旧版块更倾向于输出更多文本。比如测试一个通俗的请示“写一篇你我方的散文”,V3给出的有科技放肆感的文本不错说是“很R1”了。

DeepSeek也在证实中披露,V3-0324和之前的V3使用的base模子重迭,校正了后检修步调,并模仿了R1推理模子检修流程中的强化学习时间。
从前推理模子和非推理模子在使用时,用户很泄露的一个弃取是,非推理模子反应快,但良好和准确度上弱一些,推理模子则时时“想考”得更长远,还会给出详实的想维链,复返的适度更精准详实,但反应速率上比拟慢。
但DeepSeek似乎正在往“中间”走。
腾讯新推出的混元T1模子也有这么的特色。元宝在26日同步接入了DeepSeek的V3-0324和自研的混元T1。
T1是推理模子,可是反应速率更快。
这是因为在架构上,混元T1就物化了全Transformer,而是沿用混元TurboS的模子架构,罗致Hybrid-Mamba-Transformer。

Transformer架构擅长捕捉复杂高下文,而Mamba特长在高效处理长序列。两相讨好,模子在快与慢之间寻找均衡。
高跟美腿咱们用经典的“鸡兔同笼”题诀别向DeepSeekR1和混元T1发问,在关闭“联网搜索”的情况下,二者最终给出的谜底无误,R1想考用时28秒,T1仅用14秒。
在MMLU-pro、CEval、AIME、ZebraLogic等中英文常识、竞赛级数学,以及逻辑推理公开基准测试中,混元T1的得分并列DeepSeekR1和OpenAI的o1(均为推理模子)。
值得防备的是,混元T1每百万tokens输出价钱4元,这是DeepSeekR1圭臬时段输出价钱的四分之一,与其优惠时段价钱执平。
这么看来,腾讯不仅是在元宝接入模子的速率上看跟得紧,从模子的道路和价钱上亦然。
比亚迪对“高阶智驾”进行了从头界说。
02
侍从策略的得胜
来得早不如来得奥妙,短短一个月时候,元宝支棱起来了。
3月19日,腾讯总裁刘炽平在2024年年报电话会上提到了元宝的施展,2月到3月日活激增当先20倍,成为中国第三高的AI原生出动垄断要领。
腾讯元宝旧年5月30日发布,初期定位是集成腾讯混元大模子的智能助手,可是反响平平。1月DeepSeek的R1模子大师大火,次月腾讯就晓谕将DeepSeek-R1满血版接入元宝,由此元宝也迎来了转变点。
在那之后,元宝高强度“日更”,35天里版块更新30次。用户也不停涌入,元宝一度登顶苹果中国区垄断商店免费榜,卓越DeepSeek。
不仅是元宝,腾讯在AI界限的发力倏得按下加快键。其旗下中枢垄断如微信、QQ浏览器、QQ音乐、ima、腾讯文档等,都接入了DeepSeek模子,并同步赞成自研混元大模子。
“自研+开源”的多模子策略还将络续。腾讯方面示意,腾讯元宝将络续坚执“双模”。参加络续加大,近半个月就参加近3个亿。在前不久的财报会上,刘炽平披露:“咱们策动在2025年进一步加大成本支拨,瞻望成本支拨将占收入的十几个百分点。”
这又是一次“侍从策略”的得胜(至少是阶段性的得胜)。
紧盯市集走向,快速跟进与转变讨好,完了后发上风,这是腾讯擅长的。从腾讯“起家”的QICQ,到如今的元宝都是如斯。
腾讯也曾饱受“抄袭”“效法”的质疑。马化腾早在2010年就称“效法亦然一种尝新”,在2018年濒临记者发问时,他的复兴愈加完满:“或然候为了转变而转变,反而会让转变动作变形。好多转变时时是从下到上的,老是在不经意的边际地方出现。淌若企业都备从上至下,给转变定好地点,这么时时莫得活力,很僵化。”从与DeepSeek合作,与自研模子并行,并与里面垄断交融来看,转变不错是从下到上的,也不错是从外向内的。
在AI的牌桌上,巨头要议论的不单是是如何造出更好的模子,而是若何施展自己鸠集的居品上风,以及若何让对AI的参加和自己计谋相讨好。

在接入DeepSeek之前,腾讯在所有2024年也如故闲居部署AI,何况从中“尝到了甜头”。腾讯里面如故有当先700个业务场景接入混元大模子与加入开源大模子。全年景本开支767亿元,同比增长221%,收入同比增长11%。其中腾讯会议收入增长40%,AI功能月活增长到1500万。而企业微信收入同比翻倍。
与其说腾讯倏得“激进”了,不如说轮子落进了相宜的车辙,加快是大势所趋。
03
交融的风
马化腾在居品层面紧跟梁文锋,所有大模子行业也在随着梁文锋而动。
无须置疑的是,DeepSeekR1从本年头启动掀翻了大师“推理模子热”。AI模子求“大”不再是公认唯独可行的旅途,再经过DeepSeek对器具的不停开源,更让东谈主们有利志追求“成果”的魔力。
OpenAIo3mini、谷歌的GeminiFlashThinking;国内月之暗面的Kimi1.5,科大讯飞X1,阿里Qwen2.5-Math-PRM……
此次DeepSeek对通用模子的更新,则自满出了“交融”的趋势。V3-3024融入了R1的强化学习推理优化步调,同期保留了通用模子的高效实行性格,是龙套通用模子“无为逆境”的一种尝试。

腾讯的混元T1郑再版也有不谋而合之妙,从架构层面交融,使得其算作推理模子反应速率权贵莳植,与此同期能更好地处理高下文。DeepSeek尝试让通用模子向推理模子的地点走了走,腾讯则让推理模子向通用模子的地点走了走,两头都在向中间贴近。
模子分娩商兼顾几种旅途,导致居品线冗杂的问题如故有所显现。
此前OpenAICEO山姆·奥特曼(SamAltman)在谈及GPT-5的策动时就也曾披露,模子和居品功能太复杂,将来OpenAI将将其和谐,o3模子不再单独发布,GPT-4.5也将是OpenAI终末一个非链式想维模子。
Anthropic抢先OpenAI一步,试图给出科罚步调。在2月底发布了“大师首个夹杂模子”Claude3.7Sonnet。即在单一架构上整合及时搪塞(FastThinking)和深度想考(SlowThinking)。不让用户去在不同的模子间进行切换,而是模子自行判断现时问题是否需要深度想考。
也许接下来的问题是交融的方式采取:是通过AI自动调配来完了“交融”(试验上是将不同模子藏在后台),照旧在模子层面作念交融(就像V3-3024和腾讯混元T1郑再版的作念法)。
所谓的“两条腿走路”,是并行诱惑分离的通用模子大略推理模子。那么如今的交融趋势,即是将两条腿酿成了一个轮子奇米777me,迈左脚照旧右脚,别去畏怯了。
